|
|

| 当前位置:首页 > 机器人技术 |
最大的多模态视觉语言模型PaLM-E,5620亿参数具身多模态视觉语言模型 |
| 来源:东方证券 时间:2024/9/5 |
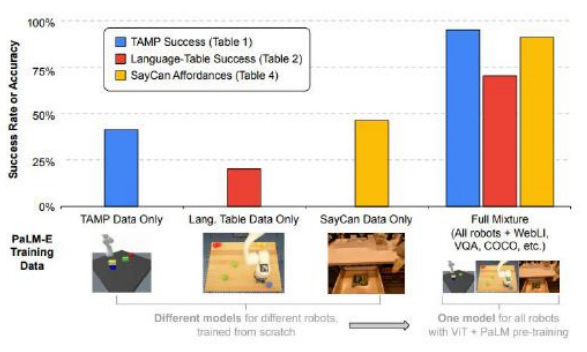
| 柏林工业大学和 Google Robotics 团队结合了 Google 当时 5400 亿参数的 PaLM 大 语言模型和 220 亿参数的 Vision Transformer(ViT)模型,提出了当时大规模的 5620 亿参数 的具身多模态视觉语言模型 (Visual Language Model, VLM)PaLM-E。在 PaLM 模型基础上, 引入了具身化和多模态概念,实现了指导现实世界机器人完成相应任务的功能。 PaLM-E 采用从多模态信息到决策端的端到端训练。PaLM-E 直接将连续的、具体的多模态观察 (如图像、状态估计或其他传感器模态),转化为和语言 token 嵌入空间维数相同的向量序列, 用和语言 token 同样的方式注入预训练语言模型的语言嵌入空间,从而在文字和感知之间建立联 系,已解决机器人相关的具身问题。模型的输入是交错的视觉、连续状态估计和文本组成的多模 态编码,然后对这些编码进行端到端训练,输出的内容则是对于机器人要执行的动作的文本决策。 整个过程不需要对场景的表示进行预处理。 以大模型作为核心的 PaLM-E 表现出了较强的泛化能力和涌现能力。研究人员发现,PaLM-E 继 承了大语言模型的核心优点:泛化和涌现能力。得益于端到端的多模态信息训练,PaLM-E 在面 对没有学习过的任务(zero-shot)时也能有很好的表现,具备将从一项任务学到的知识和技能迁 移到另一项任务的能力。经过不同任务混合训练后的 PaLM-E,与执行单一任务的机器人模型相 比,性能明显提G。同时,尽管 PaLM-E 只接受了单图像提示的训练,但却已经展示出了涌现能 力,比如多模式思维链推理(可让模型分析包括语言和视觉信息在内的一系列输入)与多图像推 理(用多个图像作为输入来做出推理或预测)。
PaLM-E 展示了大模型和机器人结合的诸多可能性。以大模型为核心的 PaLM-E 有了良好的迁移 学习能力,从而可以通过自主学习来完成长跨度规划的任务,比如,“从抽屉里拿出薯片”这类 任务包括了多个计划步骤,并且需要调用机器人摄像头的视觉反馈。经过端到端训练的 PaLM-E 可以直接从像素开始对机器人进行规划。由于模型被集成到一个控制回路中,所以机器人在拿薯 片的过程中,对途中的干扰具有鲁棒性。并且由于其采用了多模态信息作为输入,相比 ChatGPT for Robotics 论文中需要将图像信息转化为文字输入来说能够获取更多的信息,从而提升机器人模 型的性能,能够应用到更广泛的场景中。
|
| 信息推荐 |